




NodeJS是最近非常火的一个JS框架,百科的介绍是轻量高效的基于事件驱动的JS运行平台。
使用NodeJS的原因有3个,一是它的代码写法基于JS,比较容易写。已经有入门级别的经验了。另一个就是它的一个库Cheerio,可以用几乎和jQuery一模一样的方式来操作源码里面的Dom元素。这个什么意思稍候会讲。第三个是它可以做为本地端,也可以布到服务器上去。
这2天研究比较多,应该算是初级入门了。正好有个需求要处理,于是应用了NodeJS。
一、安装
网上有很多的教程,下载到https://nodejs.org,在Win系统下运行就可以搭上一个环境。下载Windows的Installer版本,双击安装,就成功了。
然后配置神器Sublime开始使用。
为Sublime添加实时调试运行,打开Sublime-》Tools-》Build System-》New Build System
在新打开的文件中写入下面的代码
{
"cmd": ["node", "$file"],
"file_regex": "^[ ]*File \"(...*?)\", line ([0-9]*)",
"selector": "source.javascript"
}
然后保存为NodeJS.sublime-build.
新建一个采集.js文件,设为NodeJS进行运行调试。

二、注意
在nodejs里面需要require(库名)的方式来引用一些外部的库,这些外部的库安装NodeJS的时候,已经放在C盘的programfiles下面了。但是直接require是无效的。
因为NodeJS提倡的是自己的代码用自己的库,所以还需要把库复制到采集.js这个文件下面。
引用的时候可以通过npm link 库名的方式,来把系统C盘的库引用到我们的项目下面。
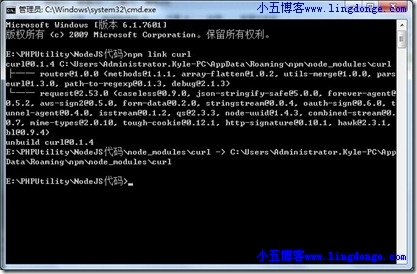
三、直接使用了
//采集页面内容到本地
var http = require("http");
var cheerio = require('cheerio'); //引用cheerio模块,使在服务器端像在客户端上操作DOM,不用正则表达式,据基准测试:cheerio大约比JsDom快8倍。
var iconv = require('iconv-lite'); //解决编码转换模块
var BufferHelper = require('bufferhelper'); //关于Buffer我后面细说
var data=download('http://blog.csdn.net/kissliux/article/details/20466889',function (data) {
//console.log(data);
var $=cheerio.load(data);//载入到cheerio进行分析
//遍历DIV
// $('a').each(function(i,e){
// console.log($(e).attr('href'));
// });
// 遍历链接
// $("a.downbtn").each(function(i, e) {
// console.log($(e).attr("href"));
// });
//var title=$('head>title').text();//读取Title信息
//console.log(title);
//分析得到页面基本信息
var page = {
"document": {
title: $('head>title').text(),
meta: {
title: $('meta[property="og:title"]').attr("content"),
author: $('meta[property="og:author"]').attr("content"),
description: $('meta[name="description"]').attr("content"),
url: $('meta[property="og:url"]').attr("content"),
type: $('meta[property="og:type"]').attr("content"),
image: $('meta[property="og:image"]').attr("content")
},
"content": undefined,
"images": []
}
};
//采集图片存入列表
$('img').each(function(){
var url = $(this).attr('src');
if (page.document.images.indexOf(url) === -1){
page.document.images.push(url);
}
});
console.log(page);
});
/**
* 下载源码,自动识别编码
* @param {[type]} url [下载URL]
* @param {Function} callback [回调]
* @return {[type]} [description]
*/
function download(url, callback) {
http.get(url, function(res) {
var data = "";
res.on('data', function (chunk) {
data += chunk;
});
res.on("end", function() {
callback(data);
});
}).on("error", function(e) {
console.log("Got error: " + e.message);
callback(null);
});
}
上面我封好了download下载Html的内容。并进行处理的简单示例。注意require的库必须使用npm link 库名克隆到本地,或者自己下载包放到采集.js下面的node_modules目录下面,如果 没有这个目录,自己创建。
其中:
使用Cheerio要取页面的H1标题就简单了
var title=$('#article_details h1 a').text().trim();//读取Div下面的H1标签文本。




文章评论 本文章有个评论