




做SEO的人应该要对搜索引擎的基本原理有一些了解,如搜索弓引擎发现网址到该页面拥有排名,以及后续更新的整个过程中,搜索引擎到底是怎么工作的。对于专业的算法不必进行深入的研究,但是对于搜索引擎工作中的策略和算法原理要有个简单的认知,这样才能更有效地开展SEO工作,知其然也要知其所以然。当然,威海SEO也有一些朋友不懂这些,照照样做得有声有色,但是对于搜索引擎工作原理,懂总比不懂要好一些。
以往的SEO书籍中对这块内容的讲解都比较简单,希望在此能够尝试结合SEO实际工作和现象,更进一步剖析一下搜索引擎的工作原理。其实当你了解了搜索引擎的工作流程、策略和基本算法后,就可以在一定程度上避免因为不当操作而带来的处罚,同时也可以快速分析出很多搜索引擎搜索结果异常的原因。有搜索行为的地方就有搜索引擎,站内搜索、全网搜索、垂直搜索等都会用到搜索引擎。接下来,威海SEO会根据从业认知,讨论一下全文搜索引擎的基本架构。百度、 Google等综合搜索巨头肯定有着更为复杂的架构和检索技术,但宏观上的基本原理都差不多。
搜索引擎的大概架构如下图所示。可以分成虚线左右两个部分:一部分是主动抓取网页进行一系列处理后建立索引,等待用户搜索;另一部分是分析用户搜索意图,展现用户所需要的搜索结果。
搜索引擎主动抓取网页,并进行内容处理、索引引部分的流程和机制一般如下。
步骤1:派出 Spider,按照一定策略把网页抓回到搜索引擎服务器;
步骤2:对抓回的网页进行链接抽离、内容处理,消除噪声、提取该页主题文本内容等;
步骤3:对网页的文本内容进行中文分词、去除停止词等;
步骤4:对网页内容进行分词后判断该页面内容与已索引网页是否有重复,剔除重复页,
对剩余网页进行倒排索引,然后等待用户户的检索。
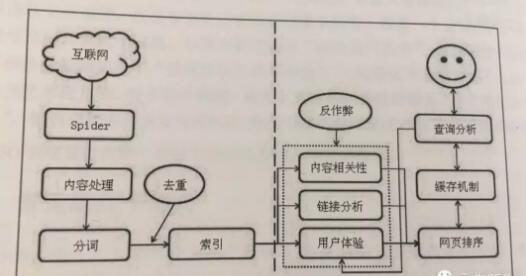
当有用户进行查询后,搜索引引擎工作的流程机制一般如下:
步骤1:先对用户所查询的关键词进行分词处理,并根据用户的地理位置和历史检索特征进行用户需求分析,以便使用地域性搜索结果和个性化搜索结果展示用户最需要的内容;
步骤2:查找缓存中是否有该关键词的查询结果,如果有,为了最快地呈现查询结果,搜索引擎会根据当下用户的各种信息判断其真正需求,对缓存中的结果进行微调或直接呈现给用户;
步骤3:如果用户所査询的关键词在缓存中不存在,那么就在索引库中的网页进行调取排名呈现,并将该关键词和对应的搜索结果加入到缓存中;
步骤4:网页排名是根据用户的搜索词和搜索需求,对索引库中的网页进行相关性、重要性(链接权重分析)和用户体验的高低进行分析所得出的。用户在搜索结果中的点击和重复搜索行为,也可以告诉搜索引擎,用户对搜索结果页的使用体验。这块儿是近来作弊最多的部分,所以这部分会伴随着搜索引擎的反作弊算法干预,有时甚至可能会进行人工干预。
按照上述搜索引擎的架构,在整个搜索引擎工作流程中大概会涉及 Spider、内容处理、分词、去重、索引、内容相关性、链接分析、判断页面用户体验、反作弊、人工于预、缓存机机制、用户需求分析等模块。以下会针对各模块进行详细讨论,也会顺带着对现在行业内讨论比较多的相关问题进行原理分析。
Spider
Spider也就是大家常说的爬虫、蜘蛛或机器人,是处于整个搜索引擎最上游的一个模块,只有 Spider抓回的页面或URL才会被索引引和参与排名。需要注意的是,只要是 Spider抓到的URL,都可能会参与排名,但参与排名的网页并不一定就被 Spider抓取到了内容,比如有些网站屏蔽搜索引擎 Spider后,虽然 Spider不能抓取网页内容,但是也会有一些域名级别的URL在搜索引擎中参与了排名(例如天猫上的很多独立域名的店铺)。根据搜索引擎的类型不同, Spider也会有不同的分类。大型搜索引擎的 Spider一般都会有以下需要解决的问题,也是和SEO密切相关的问题。




文章评论 本文章有个评论