





https://github.com/microsoft/diskspd
示例:
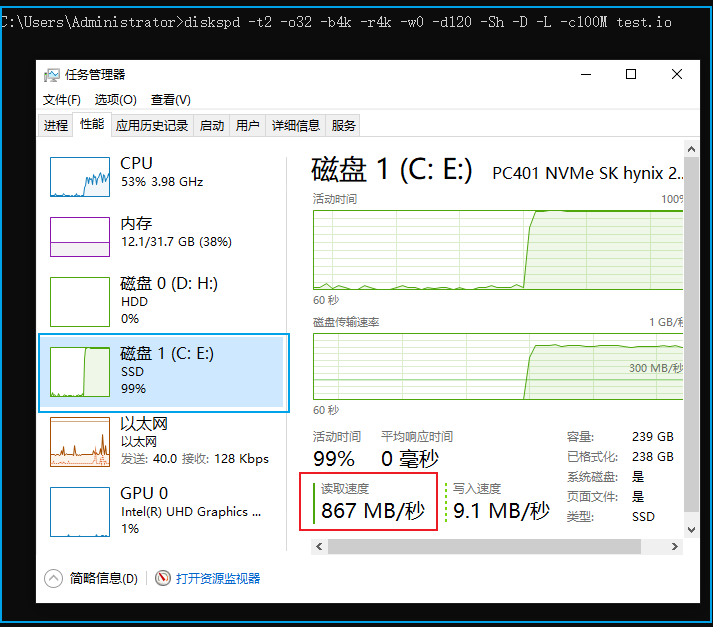
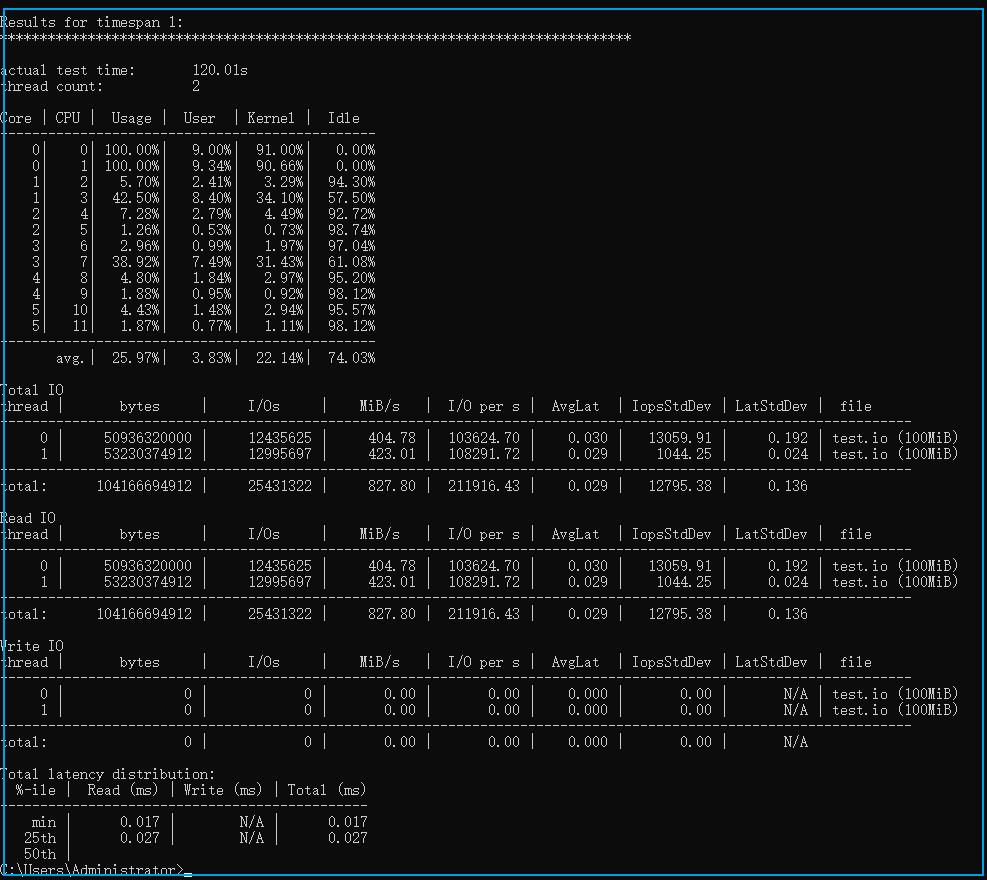
diskspd -t2 -o32 -b4k -r4k -w0 -d120 -Sh -D -L -c100M test.io
diskspd /? 帮助文档中给出的例子:-t2:这表示每个目标/测试文件的线程数。此数字通常基于 CPU 核心数。在本例中,使用两个线程来对所有 CPU 核心施加压力。
-o32:这表示每个目标每个线程的未完成 I/O 请求数。这也称为队列深度,在本例中,使用 32 来强调 CPU。
-b4K:这表示块大小(以字节、KiB、MiB 或 GiB 为单位)。在本例中,使用 4K 块大小来模拟随机 I/O 测试。
-r4K:这表示随机 I/O 与指定大小(以字节、KiB、MiB、Gib 或块为单位)对齐(覆盖-s参数)。使用常见的 4K 字节大小与块大小正确对齐。
-w0:指定写入请求操作的百分比(-w0 相当于 100% 读取)。在本例中,0% 写入用于进行简单测试。
-d120:这指定了测试的持续时间,不包括冷却或预热时间。默认值为 10 秒,但我们建议对于任何严重的工作负载至少使用 60 秒。在本例中,使用了 120 秒来尽量减少任何异常值。
-Suw:禁用软件和硬件写入缓存(相当于-Sh)。
-D:以毫秒为间隔捕获 IOPS 统计数据,例如标准偏差(每个线程、每个目标)。
-L:测量延迟统计数据。
-c100M:设置测试中使用的样本文件大小。可以以字节、KiB、MiB、GiB 或块为单位进行设置。在本例中,使用了 100M 的目标文件。
Examples:
Create 8192KB file and run read test on it for 1 second:------------------------------------创建一个8192KB的文件,并对其运行1秒的read test:
diskspd -c8192K -d1 testfile.dat
Set block size to 4KB, create 2 threads per file, 32 overlapped (outstanding)I/O operations per thread, disable all caching mechanisms and run block-aligned randomaccess read test lasting 10 seconds:-------------------------------------------将块大小设置为4KB,每个文件创建2个线程,每个线程32个重叠I/O操作,禁用所有缓存机制并运行块对齐随机访问读取测试,持续10秒:
diskspd -b4K -t2 -r -o32 -d10 -Sh testfile.dat
Create two 1GB files, set block size to 4KB, create 2 threads per file, affinitize threadsto CPUs 0 and 1 (each file will have threads affinitized to both CPUs) and run read testlasting 10 seconds:-----------------------------创建两个1GB的文件,将块大小设置为4KB,为每个文件创建2个线程,将线程关联到cpu 0和1(每个文件将有线程关联到两个cpu),并运行持续10秒的read测试:
diskspd -c1G -b4K -t2 -d10 -a0,1 testfile1.dat testfile2.dat
-
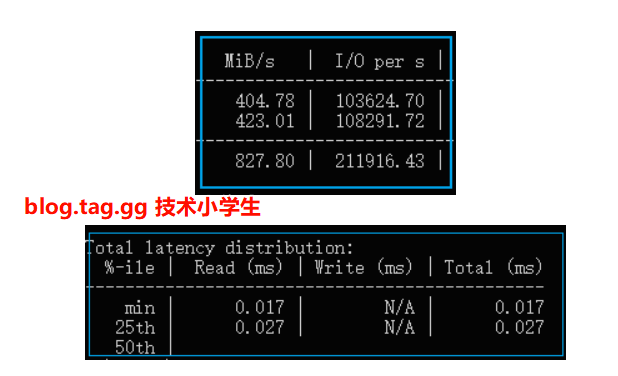
吞吐量 Throughput -
IOPS 每秒输入输出操作次数 -
延迟 Latency



文章评论 本文章有个评论